Apache Spark | Run first spark program
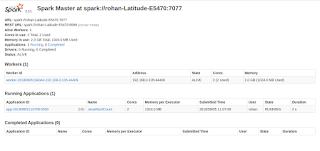
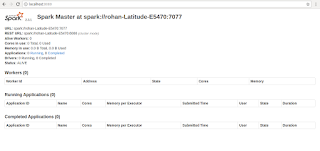
In this post we are going to run sample spark program. If you want to setup spark locally go to this post . In the last post we created slave node with 2 cores and 2g memory. This worker node will be used by master to run your spark jobs. Spark installations provides some sample programs to run on cluster. This can be found at below location. We will be running JavaWordCount program locally in spark cluster.